Summary
This paper introduces attention by name, in the context of machine translation, as a refinement of the encoder-decoder model. (Chaudhari, et al. (2021) argues that something like it was introduced earlier.)
In traditional EDMs, a single vector is passed from the encoder to the decoder. This vector must encode all of the semantics of the original sentence; word alignment is essentially lost.
To correct this, the paper adds a feed-forward layer that takes each of the encoder hidden states (“annotations”) as input, and which is used as an additional input to the decoder (alongside the preceding decoder state and the most recent token). The attention layer creates a vector that is the average of the encoder hidden states, weighted by their relevance to the current decoder state.
They introduce a network block that learns the weighting function
where
The encoder employs a bidirectional recurrent neural network (BiRNN), meaning that each annotation encodes information from throughout the input, especially from nearby words. Using global information with a contextualization mechanism foreshadows the pure attention EDM introduced in Vaswani, et al. (2017).
Metadata
- Author: Bahdanau, Cho, and Bengio (2014)
- Full Title: Neural machine translation by jointly learning to align and translate
- Category:articles
- Summary: Neural machine translation involves using a single neural network to generate translations from source sentences. A new approach called RNNsearch improves translation quality for long sentences by learning to align and translate simultaneously. Results show that this model outperforms traditional encoder-decoder models in translation tasks.
- URL: https://arxiv.org/pdf/1409.0473.pdf
Highlights
- The models proposed recently for neu- ral machine translation often belong to a family of encoder–decoders and encode a source sentence into a fixed-length vector from which a decoder generates a translation. In this paper, we conjecture that the use of a fixed-length vector is a bottleneck in improving the performance of this basic encoder–decoder architec- ture, and propose to extend this by allowing a model to automatically (soft-)search for parts of a source sentence that are relevant to predicting a target word, without having to form these parts as a hard segment explicitly. (View Highlight)
- neural machine translation attempts to build and train a single, large neural network that reads a sentence and outputs a correct translation. (View Highlight)
- An encoder neural network reads and encodes a source sen- tence into a fixed-length vector. (View Highlight)
- A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. (View Highlight)
- we introduce an extension to the encoder–decoder model which learns to align and translate jointly. (View Highlight)
- Each time the proposed model generates a word in a translation, it (soft-)searches for a set of positions in a source sentence where the most relevant information is concentrated (View Highlight)
- it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it en- codes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. (View Highlight)
- BLEU scores (View Highlight)
- Note: A metric for automatically evaluating the performance of a machine translation algorithm.
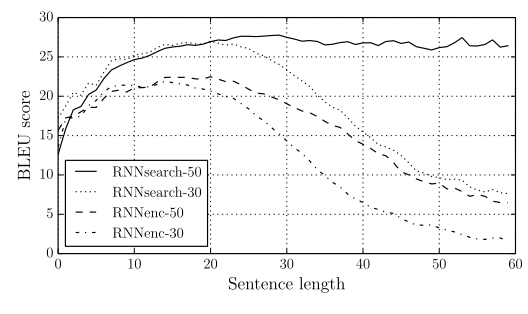 (View Highlight)
(View Highlight)
- Note: Unlike encoder-decoders, the attention-based approach remains accurate until most of the length of its parameter. At this time, I don’t know what the parameter means.
 (View Highlight)
(View Highlight)- the proposed approach achieved a translation performance comparable to the existing phrase-based statistical machine translation. It is a striking result, considering that the proposed architecture, or the whole family of neural machine translation, has only been proposed as recently as this year. (View Highlight)
New highlights added April 1, 2024 at 12:20 PM
- translation is equivalent to finding a target sentence y that max- imizes the conditional probability of y given a source sentence x, i.e., arg maxy p(y | x) (View Highlight)
- This neural machine translation approach typ- ically consists of two components, the first of which encodes a source sentence x and the second decodes to a target sentence y. (View Highlight)
- Note: The encoder hidden states represent words in the source language, and the decoder hidden states represent words in the target language. One implication of this is that, in general, the vocabulary from which the decoder samples need not be the vocabulary from which input tokens are one-hot encoded and then embedded.
- Sutskever et al. (2014) reported that the neural machine translation based on RNNs with long short- term memory (LSTM) units achieves close to the state-of-the-art performance of the conventional phrase-based machine translation system on an English-to-French translation task. (View Highlight)
- (1) (View Highlight)
- Note: The
th hidden state is computed by applying the RNN to the th input embedding and the th hidden state.
- Note: The
- q (View Highlight)
- Note: In the prior art,
is some nonlinear function that projects the hidden states of the encoder (whose dimensionality matches the input embeddings) to the vector space of the decoder.
- Note: In the prior art,
- c (View Highlight)
- Note: In the prior art,
is a fixed-length “context” vector used as the initial value (like a “0th hidden state”) of the decoder.
- Note: In the prior art,
- joint probability (View Highlight)
- Note: The probability that all of them happen together
- p(y) (View Highlight)
- Note: The decoder maximizes the product of the probability of each token given each token before it. (product=“and”)
- g (View Highlight)
- Note: Since
is returning a probability function, it is understood to include both the decoder RNN itself and the probability function that turns it into a distribution (e.g., softmax).
- Note: Since
New highlights added April 1, 2024 at 1:20 PM
- hidden (View Highlight)
- Note: Hidden in the sense of a Hidden Markov model (HMM)
- p (View Highlight)
- Note: Sampling the next token based on the PDF of the most recent hidden state is called “greedy decoding.” It’s worth noting that greedy decoding does not actually “maximize” the joint probability by choosing the next token in this way.
- bidirectional RNN (View Highlight)
- Note: An RNN that makes two passes, one forward and one backward, over the input sequence. Described in RW(Bidirectional Recurrent Neural Networks).
- x (View Highlight)
- Note:
is the actual source sentence. By contrast, in a regular EDN, you just have a
- Note:
- x (View Highlight)
- Note:
is the actual input sentence. By comparison, the regular EDN just computes the probability of conditional on preceding tokens and a fixed-length context vector, .
- Note:
- here the probability is conditioned on a distinct context vector ci for each target word yi. (View Highlight)
- The context vector ci depends on a sequence of annotations (h1, · · · , hTx ) to which an encoder maps the input sentence. Each annotation hi contains information about the whole input sequence with a strong focus on the parts surrounding the i-th word of the input sequence. (View Highlight)
- αij (View Highlight)
- Note:
is the softmax of the alignment score.
- Note:
- a (View Highlight)
- Note: a is a feedforward neural network that learns an “alignment” between decoder states (output tokens) and encoder states (input tokens).
New highlights added April 1, 2024 at 2:20 PM
- annotations (View Highlight)
- Note: This is an unusual word, with no existing baggage in the literature. It is probably meant to suggest that the hidden states encode contextual meaning.
- latent variable (View Highlight)
- Note: A variable whose value is never observed in any input or output state, but is instead learned by the model. In many cases, it’s interchangeable with Hidden (latent) state.
- We can understand the approach of taking a weighted sum of all the annotations as computing an expected annotation, where the expectation is over possible alignments. Let αij be a probability that the target word yi is aligned to, or translated from, a source word xj. Then, the i-th context vector ci is the expected annotation over all the annotations with probabilities αij. (View Highlight)
- Note: Since
is the probability that a given input token aligns to a given output token, and since the output token represents an “annotation” of the meaning of the word in context, the “expected annotation” is a representation of the meaning-in-context of an output token, given the totality of the input tokens.
- Note: Since
- The probability αij, or its associated energy eij, reflects the importance of the annotation hj with respect to the previous hidden state si−1 in deciding the next state si and generating yi. Intuitively, this implements a mechanism of attention in the decoder. (View Highlight)
- A BiRNN consists of forward and backward RNN’s. The forward RNN →− f reads the input sequence as it is ordered (from x1 to xTx) and calculates a sequence of forward hidden states ( →− h 1, · · · , The backward RNN ←− f reads the sequence in the reverse order (from xTx sequence of backward hidden states ( ←− h 1, · · · , ←− h Tx ). We obtain an annotation for each word xj by concatenating the forward hidden state backward one ←− h j, i.e., hj = −→ h j ; ←− h j →− h j and the . In this way, the annotation hj contains the summaries of both the preceding words and the following words. (View Highlight)