Summary: The text introduces the Adam algorithm for optimizing stochastic objective functions using adaptive moment estimation. Adam shows practical effectiveness compared to other stochastic optimization methods and can efficiently solve deep learning problems. The algorithm calculates adaptive learning rates for parameters based on gradient moments, providing advantages such as invariant parameter updates and compatibility with sparse gradients.
an algorithm for first-order gradient-based optimization of stochastic objective functions, based on adaptive estimates of lower-order mo- ments. (View Highlight)
Note: This ends up just being the highest element-wise absolute value in a vector, or row sum in a matrix.
I can obtain this definition by taking the limit as p approaches infinity of the definition of a p-norm.
Note: Most often, this just means that you’re using a deterministic objective (such as MSE) with noisy data. However, there are objectives that introduce their own noise term, such as the Variational autoencoder.
The focus of this paper is on the optimization of stochastic objectives with high-dimensional parameters spaces. (View Highlight)
Note: Such as training a deep learning network on noisy, real-world training data.
The method computes individual adaptive learning rates for different parameters from estimates of first and second moments of the gradients; (View Highlight)
Good default settings for the tested machine learning problems are α = 0.001,
β1 = 0.9, β2 = 0.999 and = 10−8. All operations on vectors are element-wise. With βt
1 and βt
2
we denote β1 and β2 to the power t. (View Highlight)
Note: is a small constant to prevent divide by zero.
the gradient (mt) and the squared gradient (vt) (View Highlight)
Note: The gradient acts a momentum term, and the uncentered variance sets the effective learning rate: large variance —> low learning rate (to avoid large swings)

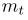 (View Highlight)
(View Highlight)
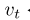 (View Highlight)
(View Highlight)